Lies, Damned Lies, Statistics,
and Probability of Abiogenesis Calculations
by Ian Musgrave
Introduction
Every so often, someone comes up with the statement "the formation of any enzyme by chance is nearly impossible,therefore abiogenesis is impossible". Often they cite an impressive looking calculation from the astrophysicist Fred Hoyle, or trot out something called "Borel's Law" to prove that life is statistically impossible. These people,including Fred, have committed one or more of the following errors.Problems with the creationists' "it's so improbable"calculations
1) They calculate the probability of the formation of a"modern" protein, or even a complete bacterium with all"modern" proteins, by random events. This is not the abiogenesis theory at all.
2) They assume that there is a fixed number of proteins, with fixed sequences for each protein, that are required for life.
3) They calculate the probability of sequential trials, rather than simultaneous trials.
4) They misunderstand what is meant by a probability calculation.
5) They seriously underestimate the number of functionalenzymes/ribozymes present in a group of random sequences.
I will try and walk people through these various errors,and show why it is not possible to do a "probability of abiogenesis" calculation in any meaningful way.
A primordial protoplasmic globule
So the calculation goes that the probability of forming a given 300 amino acid long protein (say an enzyme like carboxypeptidase) randomly is (1/20)300 or 1chance in 2.04 x 10390, which is astoundingly,mind-beggaringly improbable. This is then cranked up by adding on the probabilities of generating 400 or so similarenzymes until a figure is reached that is so huge that merely contemplating it causes your brain to dribble out your ears. This gives the impression that the formation of even the smallest organism seems totally impossible.However, this is completely incorrect.Firstly, the formation of biological polymers from monomers is a function of the laws of chemistry and biochemistry, and these are decidedly not random.
Secondly, the entire premise is incorrect to start off with, because in modern abiogenesis theories the first"living things" would be much simpler, not even a proto-bacteria, or a preproto-bacteria (what Oparin called a protobiont [8] and Woese calls a progenote [4]), but one or more simple molecules probably not more than 30-40 subunits long. Thesesimple molecules then slowly evolved into more cooperative self-replicating systems, then finally into simpleorganisms [2, 5, 10, 15,28]. An illustration comparing a hypothetical protobiont and a modern bacteria is given below.
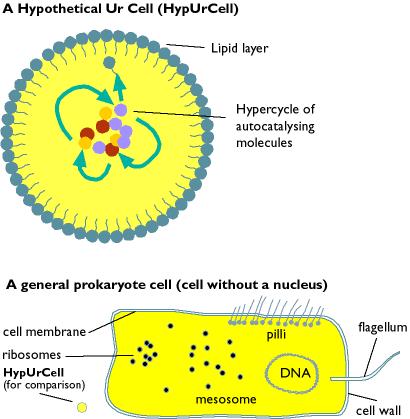
The first "living things" could have been a single self replicating molecule, similar to the"self-replicating" peptide from the Ghadiri group [7, 17],or the self replicating hexanucleotide [10], or possibly an RNA polymerase that acts on itself [12].
Another view is the first self-replicators were groups of catalysts, either protein enzymes or RNA ribozymes, that regenerated themselves as a catalytic cycle [3, 5, 15, 26, 28]. An example is the SunY three subunit self-replicator [24]. These catalytic cycles could be limited in a small pond or lagoon, or be acatalytic complex adsorbed to either clay or lipid material on clay. Given that there are many catalytic sequences in a group of random peptides or polynucleotides (see below) it's not unlikely that a small catalytic complex could be formed.
These two models are not mutually exclusive. The Ghadiripeptide can mutate and form catalytic cycles [9].
No matter whether the first self-replicators were single molecules, or complexes of small molecules, this model is nothing like Hoyle's "tornado in a junkyard making a 747".Just to hammer this home, here is a simple comparison of the theory criticized by creationists, and the actual theory of abiogenesis.

Note that the real theory has a number of small steps,and in fact I've left out some steps (especially between the hypercycle-protobiont stage) for simplicity. Each step is associated with a small increase in organization and complexity, and the chemicals slowly climb towards organism-hood, rather than making one big leap [4, 10, 15, 28].
Where the creationist idea that modern organisms form spontaneously comes from is not certain. The first modern abiogenesis formulation, the Oparin/Haldane hypothesis from the 20's, starts with simple proteins/proteinoids developing slowly into cells. Even the ideas circulating in the 1850's were not "spontaneous" theories. The nearest I can come to is Lamarck's original ideas from 1803![8]
Given that the creationists are criticizing a theory over 150 years out of date, and held by no modern evolutionary biologist, why go further? Because there are some fundamental problems in statistics and biochemistry that turn up in the semistaken "refutations".
The myth of the "life sequence"
Another claim often heard is that there is a "life sequence" of 400 proteins, and that the amino acid sequences of these proteins cannot be changed, for organisms to be alive.This, however, is nonsense. The 400 protein claim seems to come from the protein coding genome of Mycobacteriumgenetalium, which has the smallest genome currently known of any modern organism [20].However, inspection of the genome suggests that this couldbe reduced further to a minimal gene set of 256 proteins[20]. Note again that this is amodern organism. The first protobiont/progenote would have been smaller still [4], and preceded by even simpler chemical systems [3, 10, 11, 15].
As to the claim that the sequences of proteins cannot be changed, again this is nonsense. There are in most proteins regions where almost any amino acid can be substituted, and other regions where conservative substitutions (where charged amino acids can be swapped with other charged amino acids, neutral for other neutral amino acids and hydrophobic amino acids for other hydrophobic amino acids)can be made. Some functionally equivalent molecules can have between 30 - 50% of their amino acids different. In fact it is possible to substitute structurally non-identical bacterial proteins for yeast proteins, and worm proteins for human proteins, and the organisms live quite happily.
The "life sequence" is a myth.
Cointossing for beginners and macromolecular assembly
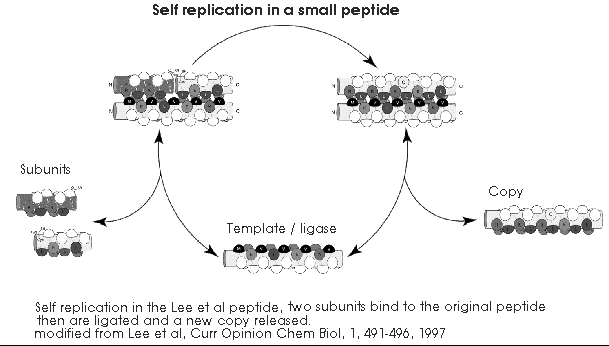
So let's play the creationist game and look at forming apeptide by random addition of amino acids. This certainly is not the way peptides formed on the early Earth, but it will be instructive.I will use as an example the "self-replicating" peptide from the Ghadiri group mentioned above [7]. I could use other examples, such as the hexanucleotide self-replicator [10], the SunY self-replicator [24] or the RNA polymerase described by the Eckland group [12], but for historical continuity with creationist claims a small peptide is ideal. This peptideis 32 amino acids long with a sequence of RMKQLEEKVYELLSKVACLEYEVARLKKVGE and is an enzyme, a peptideligase that makes a copy of itself from two 16 amino acid long subunits. It is also of a size and composition that is ideally suited to be formed by abiotic peptide synthesis.The fact that it is a self replicator is an added irony.
The probability of generating this in successive random trials is (1/20)32 or 1 chance in 4.29 x1040. This is much, much more probable than the1 in 2.04 x 10390 of the standard creationist"generating carboxypeptidase by chance" scenario, but still seems absurdly low.
However, there is another side to these probability estimates, and it hinges on the fact that most of us don't have a feeling for statistics. When someone tells us that some event has a one in a million chance of occuring, many of us expect that one million trials must be under gone before the said event turns up, but this is wrong.
Here is a experiment you can do yourself: take a coin,flip it four times, write down the results, and then do it again. How many times would you think you had to repeat this procedure (trial) before you get 4 heads in a row?
Now the probability of 4 heads in a row is is(1/2)4 or 1 chance in 16: do we have to do 16trials to get 4 heads (HHHH)? No, in successive experiments I got 11, 10, 6, 16, 1, 5, and 3 trials before HHHH turnedup. The figure 1 in 16 (or 1 in a million or 1 in1040) gives the likelihood of an event in a given trial, but doesn't say where it will occur ina series. You can flip HHHH on your very first trial(I did). Even at 1 chance in 4.29 x 1040, a self-replicator could have turned up surprisingly early.But there is more.
1 chance in 4.29 x 1040 is still orgulously,gobsmackingly unlikely; it's hard to cope with this number.Even with the argument above (you could get it on your very first trial) most people would say "surely it would still take more time than the Earth existed to make this replicator by random methods". Not really; in the above examples we were examining sequential trials, as if there was only one protein/DNA/proto-replicator being assembled per trial. In fact there would be billions of simultaneous trials as the billions of building block molecules interacted in the oceans, or on the thousands of kilometers of shorelines that could provide catalytic surfaces or templates [2,15].
Let's go back to our example with the coins. Say it takes a minute to toss the coins 4 times; to generate HHHH would take on average 8 minutes. Now get 16 friends, each with a coin, to all flip the coin simultaneously 4 times;the average time to generate HHHH is now 1 minute. Now try to flip 6 heads in a row; this has a probability of(1/2)6 or 1 in 64. This would take half an hour on average, but go out and recruit 64 people, and you can flip it in a minute. If you want to flip a sequence with a chance of 1 in a billion, just recruit the population of China to flip coins for you, you will have that sequence in no time flat.
So, if on our prebiotic earth we have a billion peptides growing simultaneously, that reduces the time taken to generate our replicator significantly.
Okay, you are looking at that number again, 1 chance in4.29 x 1040, that's a big number, and although a billion starting molecules is a lot of molecules, could we ever get enough molecules to randomly assemble our first replicator in under half a billion years?Yes, one kilogram of the amino acid arginine has2.85 x 1024 molecules in it (that's well over a billion billion); a tonne of arginine has 2.85 x1027 molecules. If you took a semi-trailer load of each amino acid and dumped it into a medium size lake,you would have enough molecules to generate our particular replicator in a few tens of years, given that you can make55 amino acid long proteins in 1 to 2 weeks [14,16].
So how does this shape up with the prebiotic Earth? Onthe early Earth it is likely that the ocean had a volume of1 x 1024 litres. Given an amino acid concentration of 1 x 10-6 M (a moderately dilute soup, see Chyba and Sagan 1992 [23]),then there are roughly 1 x 1050 potential starting chains, so that a fair number of efficent peptideligases (about 1 x 1031) could be produced in aunder a year, let alone a million years. Thesynthesis of primitive self-replicators could happenrelatively rapidly, even given a probability of 1 chance in4.29 x 1040 (and remember, our replicator could be synthesized on the very first trial).
Assume that it takes a week to generate a sequence [14,16]. Then the Ghadiriligase could be generated in one week, and any cytochrome C sequence could be generated in a bit over a million years(along with about half of all possible 101 peptide sequences, a large proportion of which will be functional proteins of some sort).
Although I have used the Ghadiri ligase as an example,as I mentioned above the same calculations can be performed for the Sun Y self replicator, or the Ekland RNA polymerase.I leave this as an exercise for the reader, but the general conclusion (you can make scads of the things in a short time) is the same for these oligo nucleotides.
Search spaces, or how many needles in the haystack?
So I've shown that generating a given small enzyme is not as given small enzyme is not as mind-bogglingly difficult as creationists(and Fred Hoyle) suggest. Another misunderstanding is that most people feel that the number of enzymes/ribozymes, letalone the ribozymal RNA polymerases or any form ofself-replicator, represent a very unlikely configuration and that the chance of a single enzyme/ribozyme forming,let alone a number of them, from random addition of amino acids/nucleotides is very small.
However, an analysis by Ekland suggests that in the sequence space of 220 nucleotide long RNA sequences, a staggering 2.5 x 10112 sequences are efficent ligases [12]. Not bad for a compound previously thought to be only structural. Going back to our primitive ocean of 1 x 1024 litres and assuming a nucleotide concentration of 1 x 10-749 potential nucleotide chains, so that a fair number of efficent RNA ligases (about 1 x 1034)could be produced in a year, let alone a million years. The potential number of RNA polymerases is high also; about 1 in every 1020 sequences is an RNA polymerase [12]. Similar considerations apply for ribosomal acyl transferases (about 1 in every1015 sequences), and ribozymal nucleotide synthesis [1, 6, 13].
Similarly, of the 1 x 10130 possible 100 unit proteins, 3.8 x 1061 represent cytochrome Calone! [29] There's lots of functional enyzmes in the peptide/nucleotide search space, so it would seem likely that a functioning ensemble of enzymes could be brewed up in an early Earth's prebiotic soup.
So, even with more realistic (if somewhat mind beggaring) figures, random assemblage of amino acids into"life-supporting" systems (whether you go for protein enzyme based hypercycles [10], RNA world systems [18], or RNA ribozyme-proteinenzyme coevolution [11, 25]) would seem to be entirely feasible,even with pessimistic figures for the original monomer concentrations [23] and synthesis times.
Conclusions
The very premise of creationists' probability calculations is incorrect in the first place as it aims at the wrong theory. Furthermore, this argument is often buttressed with statistical and biological fallacies.At the moment, since we have no idea how probable life is, it's virtually impossible to assign any meaningful probabilities to any of the steps to life except the first two (monomers to polymers p=1.0, formation of catalytic polymers p=1.0). For the replicating polymers to hypercycle transition, the probability may well be 1.0 if Kauffman is right about catalytic closure and his phase transition models, but this requires real chemistry and more detailed modeling to confirm. For the hypercycle->protobiont transition, the probability here is dependent on theoretical concepts still being developed,and is unknown.
However, in the end life's feasibility depends on chemistry and biochemistry that we are still studying, not coin flipping.


0 Comments:
Post a Comment